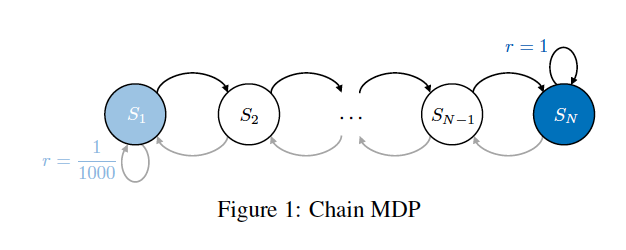
In this problem, there are $N$ states forming a chain, as in the above figure. The agent can take two actions at each step: going left ($L$) or right ($R$). At the most left state, the agent gets a reward of 1/1000 by taking $L$. In contrast, the agent gets a bigger reward of 1 by taking $R$ at the most right state. We aim to maximize the cumulative reward in a fixed number of steps.
The main difficulty of this problem is that the agent sticks to getting the small reward repeatedly, as exploring rightward states do not give any reward until it reaches the rightmost state. Bootstrapped DQN resolves this problem by boosting exploration. In brief, it uses multiple DQN agents and chooses one of the DQN agents at each episode to take greedy action with respect to the Q values the agent outputs. Then a pair of (state, action, reward, next state) is saved in the replay buffer to update each DQN agent, with their magnitude controlled by masks at each step.
However, we cannot maximize the cumulative reward by choosing the DQN agent at each step for determining actions; after the agent recognizes the whole reward structure through enough exploration, we need to exploit such information. I added an ‘exploit DQN agent’ to resolve this issue. This agent learns the reward structure consistently, and we start exploiting the agent when there is a signal of perfectly learning the reward structure.
After fine-tuning, our novel agent started to perform very well. You can check out more details in following files: Term project report, PyTorch implementation.
]]>